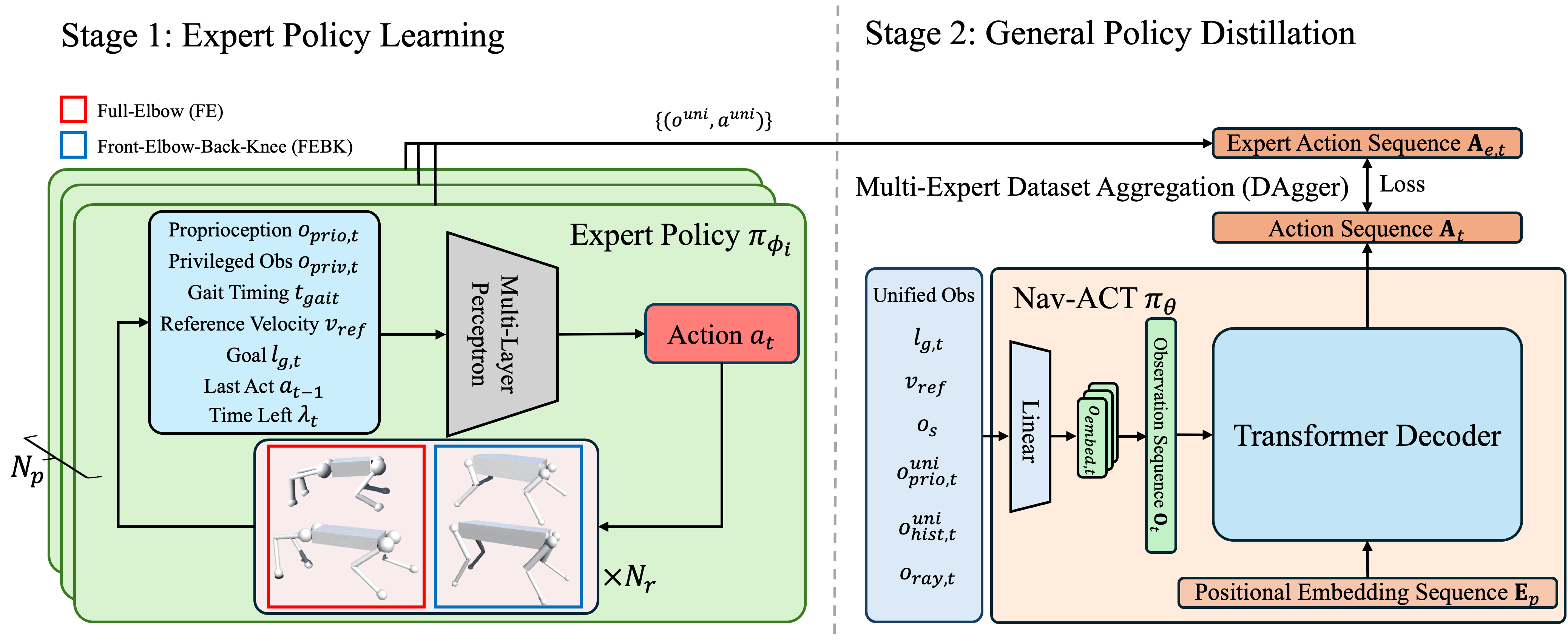
Existing navigation methods are primarily designed for specific robot embodiments, limiting their generalizability across diverse robot platforms. In this paper, we introduce X-Nav, a novel framework for end-to-end cross-embodiment navigation where a single unified policy can be deployed across various embodiments for both wheeled and quadrupedal robots. X-Nav consists of two learning stages: 1) multiple expert policies are trained using deep reinforcement learning with privileged observations using a wide range of randomly generated robot embodiments; and 2) a single general policy is distilled from the expert policies via navigation action chunking with transformer (Nav-ACT). The general policy directly maps visual and proprioceptive observations to low-level control commands, enabling generalization to novel robot embodiments. Simulated experiments demonstrated that X-Nav can effectively achieve zero-shot transfer to both unseen embodiments and photorealistic environments. A scalability study showed that the performance of X-Nav scales with the increasing number of randomly generated embodiments used during training. An ablation study confirmed the design choices of X-Nav. Furthermore, real-world experiments were conducted to validate the generalizability of X-Nav in real-world environments.